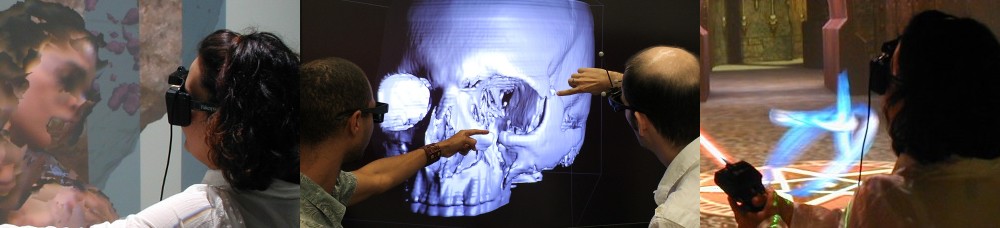
I’ve been spending all of my time over the last few weeks completely rewriting Vrui‘s collaboration infrastructure (VCI from now on), from scratch. VCI is, in a nutshell, the built-in remote collaboration / tele-presence component of my VR toolkit. Or, in other words, a networked multi-player framework. The old VCI was the technology underlying videos such as this one:
Figure 1: Collaborative exploration of a 3D CAT scan of a microbial community, between a CAVE and a 3D TV with head-tracked glasses and a tracked controller.
Or, from a slightly more whimsical headspace, this one:
Figure 2: Possibly the worst game of tic-tac-toe ever recorded.
I wrote almost all of the old VCI back in 2007 or so, and didn’t touch it much afterwards (except adding the Kinect 3D video plug-in in 2010) because I was unhappy with some of the core design decisions I had made, primarily using one communication thread per client on the server side. It never worked 100% reliably, client crashes would irritatingly often take down the entire server as well, and it was quite complex to develop new plug-in protocols for it, or new collaborative applications using it. Due to this complexity, I always dreaded fixing or rewriting it, but I am currently being paid to develop several collaborative VR visualization applications, and so I kinda had to do it now. The new design (asynchronous message exchange and event-driven I/O on the server side) is much better, 100% reliable so far, and easier to develop for, but that’s a topic for another post.
Low-latency Audio Transmission
Here I want to focus on one specific plug-in protocol, distributed audio, i.e., the component that lets multiple users sharing a virtual space talk to each other. Old VCI’s distributed audio component wasn’t great, either; it had relatively low audio quality due to the SPEEX speech codec I chose, and high latency primarily due to the old VCI’s ill-fitting core architecture.
I just spent an entire week working on the new audio component (audio and audio APIs are hard!), and it’s finally coming together quite nicely. I really like the high-fidelity voice transmission provided by the Opus codec, and the low mouth-to-ear latency mainly supported by the new VCI’s architecture as an asynchronous message exchange protocol (of course, Opus’s low-latency VoIP mode plays a role, too, but old VCI’s inherent transmission delay and packet bundling were much bigger issues).
In short, here’s how it works: On each client, local audio is captured from a microphone using the PulseAudio API. I chose PulseAudio because it is a fact of life on Linux, and because it will let me use nifty filters like echo cancellation without extra work, once I get around to that. Then, captured audio is pumped into an Opus encoder one 10ms fragment at a time, and the encoded result is immediately sent to the server in a UDP packet (or TCP segment if UDP is blocked somewhere along the way). The server then takes each incoming packet or segment and forwards it to all other clients that are within the sender’s earshot, again over UDP or TCP as a fallback. A client receiving an audio packet will feed it to its Opus decoder, and finally enqueue the decoded audio fragment at a streaming OpenAL source for 3D spatialized playback.
Jitter Buffer Optimization
So far that’s simple enough, but the devil is, as always, in the details. The problem with streaming audio is that the stream of audio packets must arrive at a client as an actual, continuous, stream, with subsequent packets exactly 10ms apart, or there will be gaps or clicks or other artifacts in playback. This is not something that happens in a packet-switched network like the Internet. The solution is to use a so-called jitter buffer, which delays incoming packets by some time while sorting them in recording order, and ensures, ideally, an uninterrupted stream of audio on the receiver end of the buffer. The secret to maximizing audio quality while minimizing latency is to carefully “center” the jitter buffer between the stream of arriving packets on one side, and the stream of audio fragments that need to be generated for artifact-free playback on the other side, and to choose the minimum jitter buffer size that guarantees an acceptable packet loss rate for a given network environment.
For example, if the arrival time of each audio packet in a stream varies at most by plus/minus one half fragment length (5ms) around the “true” average arrival time, then a properly centered jitter buffer with a single slot can guarantee that no gaps will occur (see Figure 3). If arrival times vary by plus/minus one fragment length (10ms), two slots are needed, and so forth (see Figures 4 and 5).
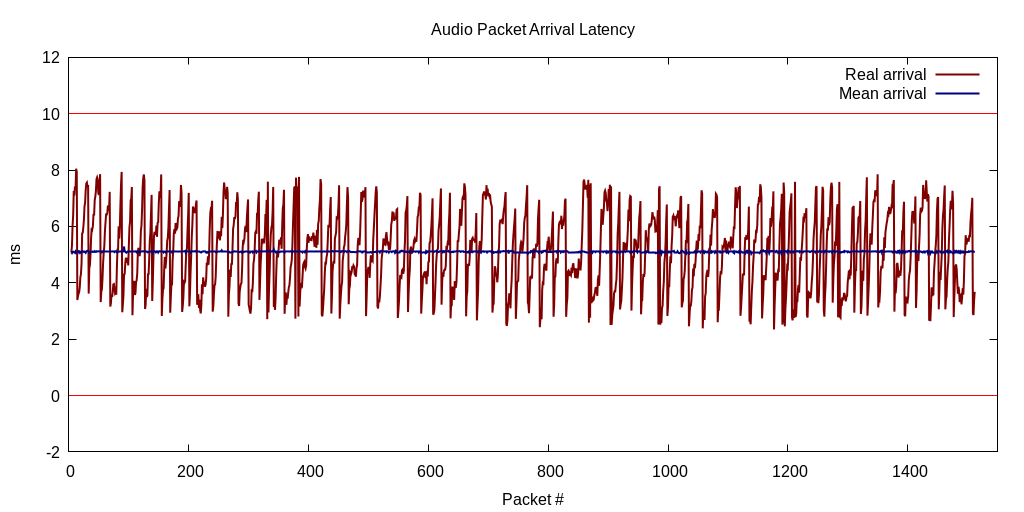
Figure 3: Latency between an audio packet arriving at the client, and being taken from the jitter buffer for two clients and the server on the same host. With a jitter buffer size of one slot, arrival latencies between 0ms and 10ms (thin red lines) will not cause audio artifacts.

Figure 4: Audio packet arrival latency with a remote yet close-by server (average ping 40ms). A one-slot jitter buffer will cause approximately 6% packet loss, which, due to Opus’s predictive packet loss concealment, is barely noticeable.

Figure 5: Same set-up as in Figure 4, but using a jitter buffer with two slots. The buffer is now centered such that mean latency is 10ms, and packet arrival time deviations of up to +-10ms do not cause artifacts. The strange spikes towards negative latencies, causing unnoticeable 1.5% packet loss, are due to my ISP going about traffic shaping in a really weird way.
The trick, then, is to keep the jitter buffer window centered on the arriving packet stream, by tracking the mean (expected) arrival time of packets over time, and nudging the playback stream gently forward and backwards in time to align it by compressing or stretching the played audio, respectively (which can be seen happening during the first 100 packets or so in Figures 4 and 5).
Mouth-to-ear Latency
With this system in place, it is now possible to monitor the incoming packet stream and calculate its packet arrival time variance, and then automatically adapt the jitter buffer size for minimum latency given an acceptable packet loss rate. The final question, then, is what total latency, from one person making a sound to another person hearing it, can be achieved under different network conditions. In general, total audio latency is the sum of several components:
- Inherent latency in sound hardware, i.e., latency of the analog-to-digital (ADC) and digital-to-analog converters (DAC) used by the source and sink, respectively.
- Latency from fragment-based digital audio capture and playback. For example, if audio is captured in fragments of 10ms, then the minimal latency between a sound being digitized and being delivered by the audio hardware is 10ms.
- Latency from intermediate sound processing/transmission software such as Linux’s PulseAudio.
- Latency from audio encoding and decoding, which is a combination of the actual time it takes to encode/decode one fragment of audio, plus any internal pre-buffering/look-ahead done by the audio codec.
- Latency from network transmission. This, of course, depends on distances between the server and the clients, network congestion, intermediate traffic shaping, and can vary significantly during the lifetime of a connection.
- Latency from stream smoothing, i.e., operation of the jitter buffer.
- Latency from audio spatialization and mixing, plus potential 3D effects processing, using a 3D sound system such as OpenAL.
To investigate this, I started by looking at inherent latency from sound hardware and fragment-based capture/playback by connecting my sound card’s line-in port to its line-out port using a loopback cable (so Lighthouse’s base station synchronization cable has its uses after all), and writing a small program that captures audio and plays it back immediately within the same process. This program zeros out the first two seconds of audio to give the sound system time to stabilize, and then inserts a very short and strong pulse into the captured audio. Some time later, this pulse will make its way to the sink DAC, then to the line-out port and back into the line-in port and the source ADC, where it will show up in the captured audio stream again. By measuring the distance between the original pulse and its first copy, one can precisely measure total microphone-to-speaker latency down to the sample (20.833μs for 48kHz sample rate). Figures 6 and 7 show an example wave form collected by such an experiment.
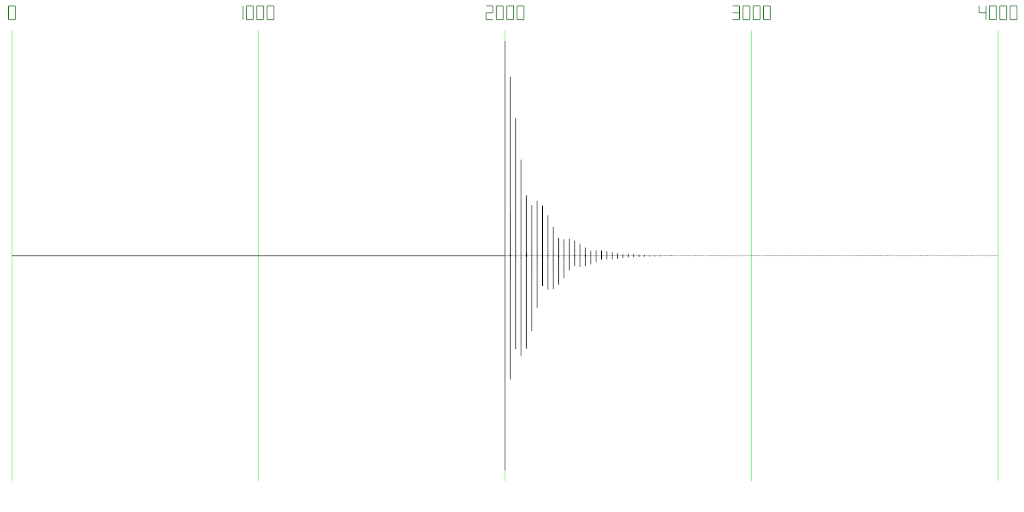
Figure 6: Waveform generated by a loop-back latency test. 2s of silence are followed by a single click inserted into the audio stream, which is played back and picked up again some time later, then played back and picked up again, and so forth (time stamps in ms).
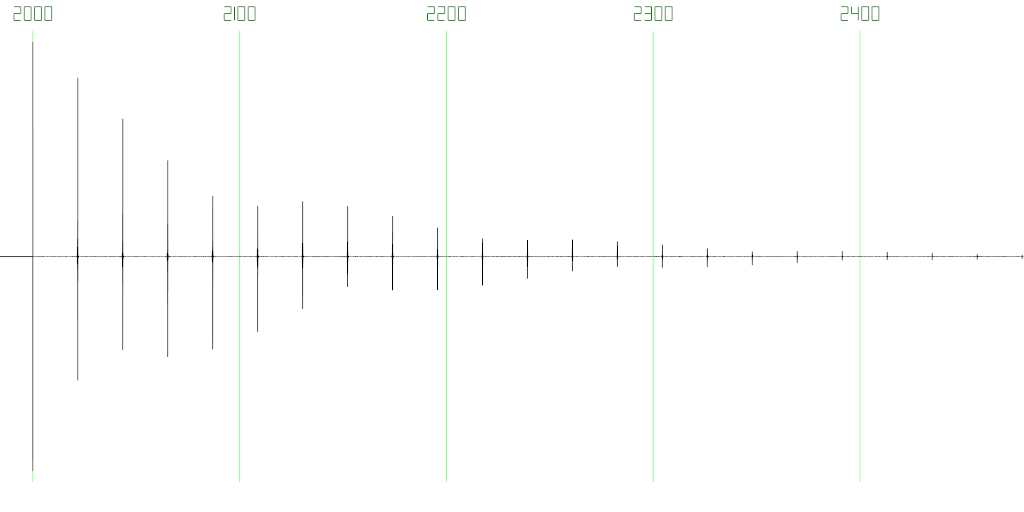
Figure 7: Zoomed-in view of Figure 6, showing the original click at 2000ms, and its exponentially decaying copies following at equal intervals.
In the first test, to get a latency baseline, I captured and played back directly from/to my sound card using Linux’s native ALSA kernel API. Using a 5ms fragment length and 2ms pre-buffering in the playback stream, I was able to achieve a total latency of 8.26ms (see Figure 8).

Figure 8: Round-trip latency using ALSA API and fragment size of 5ms and 2ms pre-buffering is 8.26ms.
Repeating the experiment with a fragment size of 10ms, still using 2ms pre-buffering, resulted in a total latency of 13.28ms (see Figure 9).
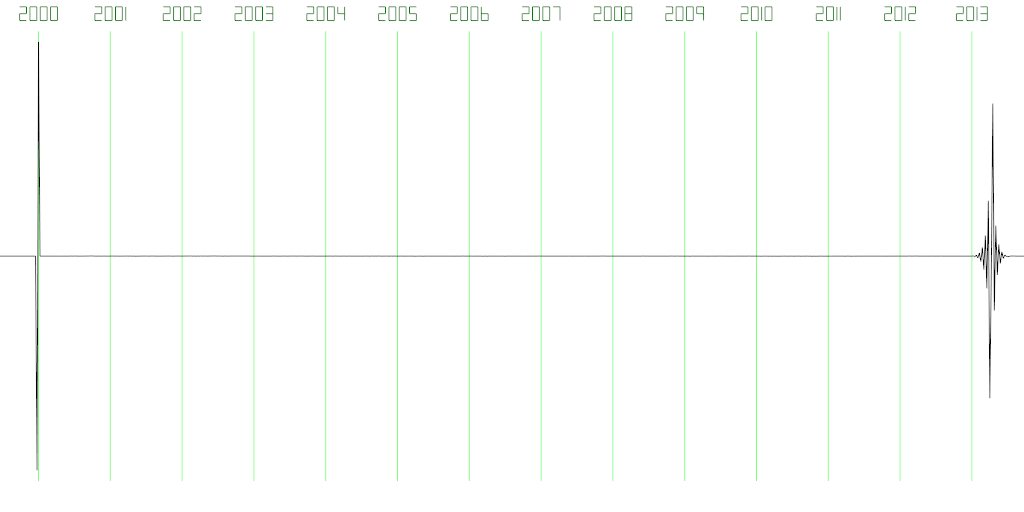
Figure 9: Same set-up as Figure 8, with fragment size 10ms, results in 13.28ms latency.
A final experiment with 20ms fragment size and 2ms pre-buffering resulted in a total latency of 23.28ms (see Figure 10).

Figure 10: Same set-up as Figures 8 and 9, but using 20ms fragment size, yields 23.28ms total latency.
These results are highly consistent: a fragment-processing latency of 5ms, 10ms, and 20ms, plus pre-buffering latency of 2ms, yield 7ms, 12ms, and 22ms, respectively, leaving 1.26ms, 1.28ms, and 1.28ms again, which can then be chalked up to inherent hardware latency of 1.27ms on average (I’m including in-kernel processing and context switch time in “hardware latency” here).
For the next test, I used the ALSA interface and 5ms fragment size again, but this time captured from and played back to the “default” virtual sound card, to measure the additional latency introduced by the PulseAudio sound system (see Figure 11). PulseAudio has a reputation as a latency killer and as “the sound solution that nobody asked for,” and this first test bears that out: total latency jumped from 8.26ms to 21.72ms.

Figure 11: Latency test with 5ms fragment size and 2ms pre-buffering using ALSA to access a virtual sound card represented by the PulseAudio sound system, with a total latency of 21.72ms.
Now, in all fairness, this was hardly a very direct way to go about it. I used the ALSA API to access PulseAudio, via a virtual sound card managed by a PulseAudio plug-in, which then in turn talked to the real sound hardware using the actual in-kernel ALSA API. So I decided to re-run the test directly using the PulseAudio API, which took a not-insignificant bite out of my week due to PulseAudio’s somewhat sparse documentation. In short, there are two API modes: “simple” and “asynchronous.” “Simple” is indeed simple, but doesn’t allow much tweaking and has so-so latency (14.9ms, figure omitted), whereas “asynchronous” is much more complex and does not have a single usage example anywhere in the documentation. I did manage to get it going, after a good amount of trial and error specifically regarding resource management, and lots of segmentation faults, and was rewarded with a total latency of 11.5ms (figure omitted). I decided that to be good enough, given the ubiquity of PulseAudio on Linux, and the potential benefits from using sound processing plug-ins later on for no additional effort on my part. With that in mind, I do think that PulseAudio’s reputation is maybe somewhat undeserved. It does quite a lot of useful stuff for 3.24ms of additional sound latency.
With these measurements on the books, I decided to use PulseAudio as my audio capture API, and OpenAL, mixing to a PulseAudio back-end by default, as my playback API. I initially tried using OpenAL for audio capture as well, which was tempting due to its simplicity and portability, but the latency results were beyond the pale. It turns out that OpenAL capture has no tunable parameters, and defaults to capturing audio in fragments of 40ms, which would have meant an additional 30ms latency on the capture side, and then an additional 4 slots in the jitter buffer on the playback side, on top of what’s required by network transmission variance, to handle the highly irregular packet arrival pattern. With asynchronous PulseAudio capture, on the other hand, 10ms fragments arrive at the audio encoder at 10ms intervals, like clockwork.
Full Pipeline Latency
With an asynchronous-API PulseAudio capture module, an Opus encoder, an adaptive jitter buffer, an asynchronous packet exchange server, an Opus decoder, and a short-queue OpenAL streaming source in hand, I was finally able to measure the total mouth-to-ear latency of new VCI’s distributed audio pipeline. I followed the same approach as in the earlier tests: a loop-back cable connecting my sound card’s line-out to line-in, but now with two VCI clients running as independent processes on that same computer, and a VCI server running somewhere else to simulate communication with remote clients. In that set-up, audio is captured by one client, encoded and sent to the server, which forwards the encoded audio to the second client (which happens to run on the same computer as the first), which in turn decodes the audio and plays it to line-out, where it loops around to line-in, gets picked up again by the first client, and round and round it goes.
Without further ado, here are the results. The first test had the VCI server running on the same computer as the two VCI clients, for basically zero network transmission latency (this set-up was also the source for the jitter buffer data in Figure 3). Total round-trip latency using a one-slot jitter buffer was 40.6ms (see Figure 12), at 0% packet loss rate and perfect audio quality.

Figure 12: Total VCI audio pipeline latency between two clients and a server all running on the same host, yielding 40.6ms. Jitter buffer size: one slot, packet loss rate: 0%. See Figure 3 for packet arrival time variance resulting from OS scheduling, CPU load, etc.
For the second test, I ran the two clients on the same computer as before, but ran the server on my laptop instead, connected to the clients over 2.4GHz Wi-Fi and an intermediate GigE switch. Still using a one-slot jitter buffer, the resulting latency was 44.38ms (see Figure 13), at 0% packet loss rate and perfect audio quality. Interestingly, ICMP ping round-trips between those two computers were highly variable, careening from 1.5ms to 70ms on the immediate next packet and back again, but once the audio stream got going, round-trip variance was very low. I should also explicitly point out that all audio data was going over Wi-Fi twice, once from client 1 to the server, and the second time from the server to client 2.
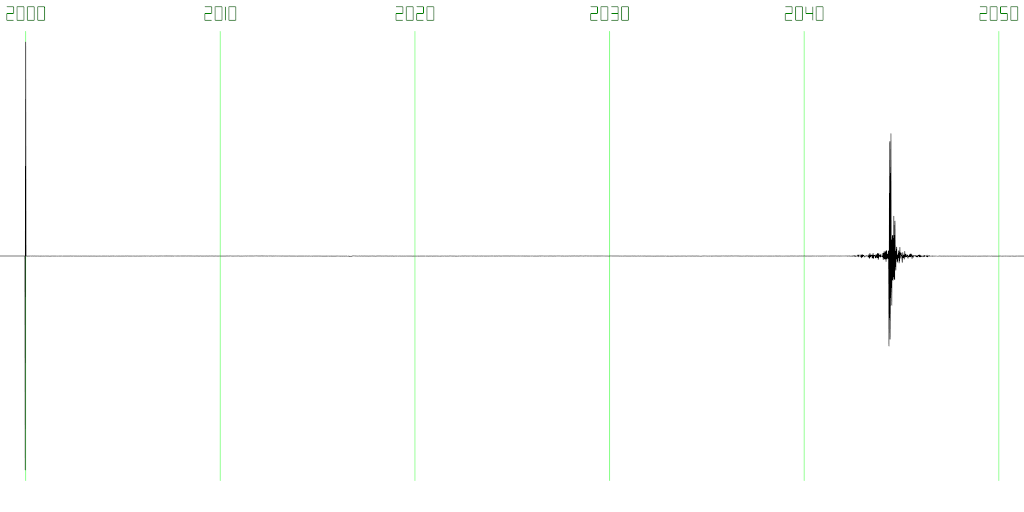
Figure 13: Total VCI latency over a 2.4GHz Wi-Fi connection between the server and both clients. Total latency using a one-slot jitter buffer was 44.38ms, with 0% packet loss rate.
My final two tests were between two clients running on the same host as before, and the server running on a “remote” Internet host; concretely, the PC under my desk at UC Davis. While that computer is relatively close to my home PC (around 10 miles as the crow flies and 30 hops as the IP packet goes — as per traceroute — with 30-40ms ICMP ping on average), ping time between the two is highly irregular, due to my ISP doing some really weird things (see packet arrival times in Figures 4 and 5). At first, I tried a one-slot jitter buffer, resulting in 78.69ms latency at the price of 6% packet loss rate (see Figure 14). Still, the loss in audio quality was barely noticeable, owing to the Opus codec’s excellent forward error correction and packet loss concealment.

Figure 14: Total VCI latency over a regular home Internet connection between a remote server and two local clients. Total latency using a one-slot jitter buffer was 78.69ms, with 6% packet loss rate due to the packet arrival time spikes shown in Figure 4.
To improve audio quality for the final test, I increased jitter buffer size to two slots, increasing latency to 82.25ms and reducing packet loss rate to 1.5%, which was unnoticeable in terms of audio quality (see Figure 15).
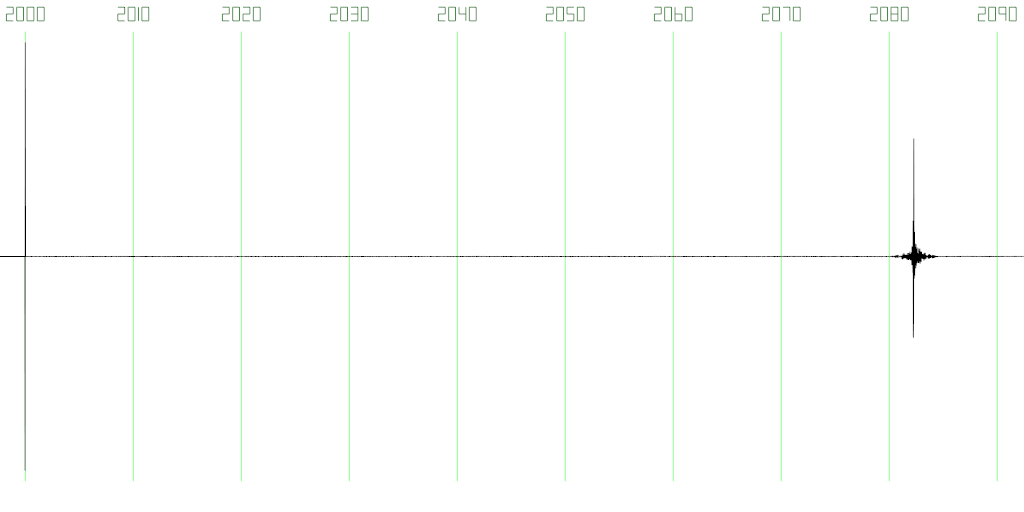
Figure 15: Total VCI latency on the same set-up as in Figure 14, but using a two-slot jitter buffer. Total latency was 82.25ms, with 1.5% packet loss rate due to the packet arrival time spikes shown in Figure 5.
These results are nicely consistent. Without network delay, mouth-to-ear latency between two clients is 40.6ms, and after adding 30-40ms of network delay, latency ends up at 70-80ms. Increasing jitter buffer size by one slot adds 5ms of latency, as predicted. Given the data shown in Figures 4 and 5, widening the jitter buffer to three slots would have yielded a latency of about 87ms, and close to zero packet loss (in these experiments, no audio packets were actually lost — they merely arrived outside the jitter buffer’s active window).
Further Improvements
Based on the results from the previous section, I dare to predict that VCI’s total audio latency is 41ms plus the total network latency between two communicating clients, plus 5ms for each additional jitter buffer slot required to mask network latency variance, which comes out to 1 additional slot, or 5ms additional latency, for each 5ms of variance. I don’t actually know how that compares to other VoIP solutions such as Skype or TeamSpeak or Mumble (which I hear is really great with latency), but I don’t think it’s too shabby.
There is one area of potential improvement that I haven’t yet been able to investigate, however. As I mentioned, I am using OpenAL for sound spatialization and mixing on the playback side. Spatial sound is a requirement for a VR distributed audio system, as remote user’s voices must appear to emanate from their avatar’s mouths, but OpenAL is completely opaque regarding its back-end handling and resulting latency, and given my bad experience with OpenAL capture (I didn’t dare mention it earlier, but the initial OpenAL-to-OpenAL implementation of VCI had 113(!)ms latency between two clients and a server all on the same host), I’m worried it might be wasting a lot of precious time.
Concretely, the 29ms latency difference between straight PulseAudio-to-PulseAudio and PulseAudio-to-Opus-to-OpenAL-to-PulseAudio is not fully explained by intermediate audio encoding and decoding (which takes 2ms total), Opus internal look-ahead, 5ms latency from a one-slot jitter buffer, and 5ms pre-buffering on the OpenAL source. Unfortunately, I wasn’t yet able to implement a non-spatial test version of VCI audio using straight PulseAudio (or even ALSA to raw hardware) on the playback side, due to on-going problems with the PulseAudio API. But if that turns out to shave off a lot, it would make it worthwhile to investigate OpenAL much more closely by looking at the source, and seeing if there’s maybe something that can be done.
Specifically, there are a few ways to tune OpenAL’s playback buffer management. Some parameters are exposed via a session-wide configuration file (~/.alsoftrc), where I can set the mixing frequency to 48000Hz, the period size to 480 samples (10ms), and the number of periods, whatever that means exactly, to 1, 2, or 3.
But regardless of these potential improvements, I am very happy with the current state of new VCI’s distributed audio component, and am looking forward to field-testing it in collaborative VR environments here at UC Davis and elsewhere, and to post additional reports as to VCI’s on-going development here.
To play us out, here’s a video showing two users messing around with chains of carbon atoms in the collaborative Nanotech Construction Kit, which is currently still based on the old Vrui Collaboration Infrastructure, recorded in UC Davis ModLab‘s two-Vive collaborative VR environment:
