Note: I started writing this article in June 2017, because people kept asking me about details of the PS Move tracking algorithm I implemented for the video in Figure 1. But I never finished it because I couldn’t find the time to do all the measurements needed for a thorough error analysis, and also because the derivation of the linear system at the core of the algorithm really needed some explanatory diagrams, and those take a lot of work. So the article stayed on the shelf. I’m finally publishing it today, without error analysis or diagrams, because people are still asking me about details of the algorithm, more than four years after I published the video. 🙂
This one is long overdue. Back in 2015, on September 30th to be precise, I uploaded a video showing preliminary results from a surprisingly robust optical 3D tracking algorithm I had cooked up specifically to track PS Move controllers using a standard webcam (see Figure 1).
Figure 1: A video showing my PS Move tracking algorithm, and my surprised face.
During discussion of that video, I promised to write up the algorithm I used, and to release source code. But as it sometimes happens, I didn’t do either. I was just reminded of that by an email I received from one of the PS Move API developers. So, almost two years late, here is a description of the algorithm. Given that PSVR is now being sold in stores, and that PS Move controllers are more wide-spread than ever, and given that the algorithm is interesting in its own right, it might still be useful.
The Problem
The PS Move controller has two devices that allow it to be tracked in three dimensions: an inertial measurement unit (IMU), and a rubbery sphere that can be illuminated — in all colors of the rainbow! — by an RGB LED inside the sphere. As I have discussed ad nauseam before, an IMU by itself is not sufficient to track the 3D position of an object over time. It needs to be backed up by an external absolute reference system to eliminate drift. That leaves the glowy ball, and the question of how to determine the 3D position of a sphere using a standard camera. In principle, this is possible. In practice, as always, there are multiple ways of going about it.
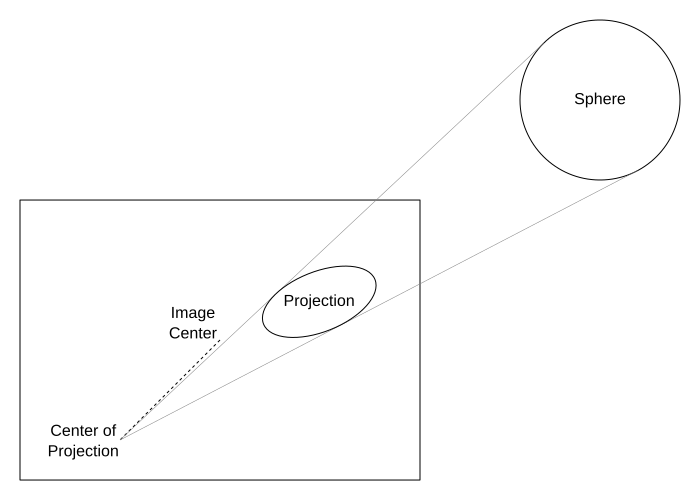
Figure 2: The projection of a sphere onto a pinhole camera’s image plane is an ellipse whose major axis points towards the image center.
A 2D Approach
To an idealized pinhole camera, a sphere of uniform brightness (fortunately, Sony’s engineers did a great job in picking the diffuse ball material) looks like an ellipse of uniform color (see Figure 2). Based on the position of that ellipse in the camera’s image plane, one can calculate a ray in 3D camera space (where the projection center is the origin, and the viewing direction runs along the negative Z axis), and based on the ellipse’s apparent size, one can calculate a distance along that 3D ray. Together, those two define a unique point in 3D space. The algorithm breaks down as follows:
- Identify the set of pixels belonging to the sphere’s projection.
- Calculate the parameters of an ellipse fitting the outer boundary of the set of identified pixels.
- Calculate a 3D position such that the projection of a sphere of known radius at that position matches the observed ellipse.
Step 1 is a basic image processing problem, namely blob extraction. Step 2 is more tricky, as fitting an ellipse to a set of pixels is a non-linear optimization problem, which is difficult to implement efficiently. Step 3 is also difficult, but for fundamental mathematical reasons.
No matter the representation, uniquely identifying an ellipse requires five parameters. One representation could be (center x and y; major axis; minor axis; rotation angle). Another one could be (focal point 1 x and y; focal point 2 x and y; total chord length). But identifying a sphere in 3D space requires only four parameters (center point x, y, and z; radius). Therefore, there must be an infinity of 2D ellipses that do not correspond to any possible projection of a 3D sphere onto a pinhole camera’s image plane. However, the ellipse fitting algorithm in step 2 does not know that. Under real-world conditions, one would expect to receive parameters that — at best — merely resemble a projected sphere. On top of that, calculating the sphere parameters that correspond to a projected ellipse, even assuming there is such a sphere in the first place, is another tricky non-linear optimization problem (for example, the projection of the sphere’s center is not the center of the projected ellipse). In practice, this means most 2D approaches to the problem involve some guesswork or heuristics, and are not particularly robust against noise or partial occlusion.
A 3D Approach
Given the 2D approach’s issues, would it be possible to solve the problem directly in three dimensions? The answer is yes, and the surprising part is that the 3D approach is much simpler.
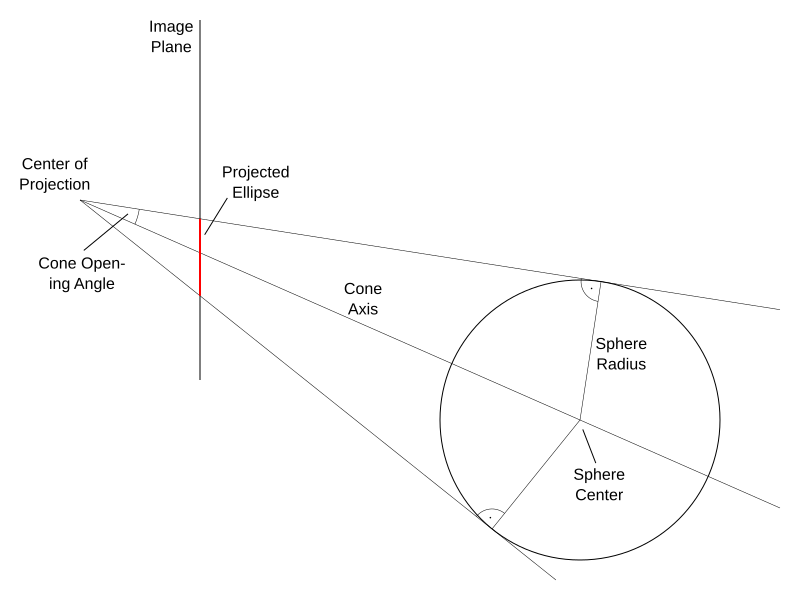
Figure 3: A sphere enveloped by a 3D cone whose apex is at a camera’s center of projection.
Imagine, if you will, a sphere in 3D space, and a 3D point that is somewhere outside the sphere. Those two together uniquely identify a cone whose apex is at the imagined point, and whose mantle exactly touches the imagined sphere (see Figure 3). Now, without loss of generality, assume that the imagined point is at the origin of some 3D coordinate system, for example the origin of a 3D camera-centered system, i.e., the camera’s focal point. Then, assuming that the sphere’s radius is known a priori, its remaining three parameters have a 1:1 correspondence with the three parameters defining the cone (axis direction, which only has two free parameters due to its unit length, and opening angle). In other words, if one has the parameters of a cone touching a sphere, and the sphere’s radius, one has the 3D position of that sphere relative to the cone’s apex.
Even better, calculating the sphere’s parameters from the cone’s is simple trigonometry: the sphere’s center must be somewhere along the cone’s axis, and due to the cone’s enveloping nature, any ray along the cone’s mantle, a radius from the center of the sphere to the point where that ray touches the sphere, and the cone’s axis form a right triangle. Thus, distance along the ray is d = r / sin(α), where r is the sphere’s radius, and α is the cone’s opening angle.
How does this help, when all one has is a set of pixels in a camera’s image that belong to the projection of a sphere? First, and this is yet another basic image processing problem, one reduces the set of pixels to its boundary, i.e., only those pixels that have at least one neighbor that is not itself part of the set. That set of pixels, in turn, defines a set of 3D lines through the camera’s focal point, whose direction vectors can be calculated from the camera’s intrinsic projection parameters, which are assumed to be known a priori. The important observation, now, is that the 3D lines corresponding to those boundary pixels in the camera’s image must be part of the imaginary cone’s mantle, because they all go through the cone’s apex (the camera’s focal point), and all touch the sphere.
Therefore, given a set of 2D pixels in a camera image (or their corresponding lines in 3D camera space), we can calculate the parameters of the unique cone fitting all these lines by solving a large set of equations. Assuming that each line already goes through the cone’s apex, which is a given based on how a camera works, when does a line lie inside a cone’s mantle? The geometric definition of a cone is the 2D surface swept out by a line going through a fixed point (the cone’s apex, check!) rotating around another fixed line going through the same fixed point (the cone’s axis). In other words, all lines in the cone’s mantle form the same angle with the cone’s axis (the cone’s opening angle).
Using vector algebra, the angle between two direction vectors p and a is calculated as cos(α) = p·a / (|p|·|a|), where p·a is a vector dot product, and |p| and |a| are the Euclidean lengths of vectors p and a, respectively. Or, if p and a are 3D Cartesian vectors a = (ax, ay, az)T and p = (px, py, pz)T, then p·a = px·ax+py·ay+pz·az, |p| = √(px·px+py·py+pz·pz), and |a| = √(ax·ax+ay·ay+az·az).
In other words, each boundary pixel’s line direction pi defines an equation cos(α) = pi·a / (|pi|·|a|), where a and α are the unknown cone parameters. Together with an additional equation restricting a to unit length, i.e., |a| = 1, this system solves the problem. Unfortunately, this is still a non-linear system (the unknowns ax, ay, and az appear squared and underneath a square root), and a large one at that (with one non-linear equation per boundary pixel), which means it is still difficult to solve.
Fortunately, there is a way to restate the problem that turns the system into a linear one, and best of all — it is not an approximation! The trick, as so often, is to express the system of equations using different unknowns. Let us look at a and α again. Due to the camera being a real camera, we know that az, the third Cartesian component of a, is always smaller than zero (I mentioned above that in the canonical camera system, the camera looks along the negative Z axis). That means we can divide vector a by the negative of its third component, yielding a‘ = a/-az = (ax/-az, ay/-az, -1)T = (ax’, ay’, -1)T. Turning this around yields a = a‘·(-az), and we can now rewrite the original equation as cos(α) = p·(a‘·(-az)) / (|p|·|a‘·(-az)|).
But didn’t this just complicate matters? Turns out, things are not as they seem. Dot product and Euclidean length are linear operators, meaning we can pull the “·(-az)” out of both, remembering that |a‘·(-az)| = |a‘|·(-az) because az is negative, and then cancel the one in the numerator with the one in the denominator, resulting in cos(α) = p·a‘ / (|p|·|a‘|). And lo, given that a‘ only has two unknowns, ax’ and ay’, we just eliminated a variable — leaving us three, exactly the number we expected based on the problem statement!
Now we multiply both sides by (|p|·|a‘|), yielding cos(α)·(|p|·|a‘|) = p·a‘, re-arrange the terms on the left side to form (cos(α)·|a‘|)·|p| = p·a‘, and finally introduce a new unknown az’ = cos(α)·|a‘|. This reduces the original equation to az’·|p| = p·a‘, or, spelled out, az’·√(px·px+py·py+pz·pz) = px·ax’+py·ay’-pz, which is a linear equation in the three unknowns ax’, ay’, and az’. Well done!
Given a set of n≥3 line directions pi calculated from boundary pixels, these equations form an over-determined linear system M·(ax’, ay’, az’)T = b, where M is an n×3 matrix whose rows have the form (pxi, pyi, -√(pxi·pxi+pyi·pyi+pzi·pzi)), and b = (pz1, …, pzn) is an n-vector. This system can be solved easily, and very quickly, using the linear least squares method MT·M·(ax’, ay’, az’)T = MT·b, where MT·M is a 3×3 matrix, and MT·b is a 3-vector.
The final step is to extract the cone’s axis and angle, and the resulting sphere position, from the system’s solution vector (ax’, ay’, az’)T: the cone’s (non-normalized) axis direction is a = (ax’, ay’, -1)T, the axis length is |a| = √(ax’·ax’+ay’·ay’+1), therefore the normalized axis is a/|a|, and the opening angle is α = cos-1(az’/|a|). And at last, the sphere’s position is p = (a/|a|)·r/sin(α) = a·r/(|a|·sin(cos-1(az’/|a|))), where r is the sphere’s radius.
Implementation Details
The 3D algorithm described above is really quite elegant, but there are some details left to mop up. Most importantly, and that should go without saying, getting good 3D position estimates from this algorithm — or from any other algorithm solving the same problem, for that matter — requires that the calculation of 3D line directions from image pixels is as accurate as possible. This, in turn, requires precise knowledge of the camera’s intrinsic projection parameters and its lens distortion correction coefficients. It is therefore necessary to run a good-quality camera calibration routine prior to using it in applications that require accurate tracking.
Second, the algorithm’s description calls for 3D line directions that touch the 3D sphere, but as written above, using boundary “inside” pixels does not yield that. An “inside” pixel with “outside” neighbors does not define a line tangential to the sphere, but a line that intersects the sphere. This results in the cone’s opening angle being under-estimated, and the resulting distance between the sphere and the camera’s focal point being over-estimated. A simple trick can remove this systematic bias: instead of using the 3D line direction defined by a boundary inside pixel, one uses the direction halfway between that inside pixel and its outside neighbor.
Robustness
As apparent in the video in Figure 1, the tracking algorithm is surprisingly robust against partial occlusion of the tracked sphere. How is this possible? The described algorithm assumes that the boundary of the set of pixels identified as belonging to the sphere all lie on the mantle of a cone enveloping the sphere, but if the sphere is partially occluded, some boundary pixels will lie inside of the cone, leading to a wrong estimate of both axis direction and opening angle.
I addressed this issue by iterating the cone extraction algorithm, based on the observation that interior boundary pixels cause the cone’s opening angle to be under-estimated. Meaning, true boundary pixels will generally end up outside the estimated cone, while false boundary pixels will generally end up inside. Therefore I initially extract the full boundary, B0, of the set of pixels identified as belonging to the sphere. Then I iterate the following, starting with i = 0:
- Fit a cone to the set of pixels Bi.
- Remove all pixels that are inside the cone by more than some distance ε from set B0 to form set Bi+1.
- If there were points inside the cone, and i is not larger than some maximum, repeat from step 1 with pixel set Bi+1.
In my experiments, this iteration converged rapidly towards the true set of tangential boundary pixels, needing no more than five iterations in all situations I tested.
Error Analysis
I said there would be no error analysis, but I lied. I found a graph (see Figure 4) with data from an experiment I ran when I started discussing tracking error with Alan Yates in the comments of the YouTube video shown in Figure 1. I had forgotten about that.

Figure 4: Graph showing results of PS Move tracking experiment. See below for legend.
I made the graph in Figure 4 in LibreOffice Calc, and it ate my axis and series labels in revenge. Here’s a legend/rough analysis:
- The X axis is the real Z position of the glowing ball relative to the camera, in millimeters. I took measurements between 0.3m and 2.4m (one foot and eight feet actually).
- The orange and blue curves are the real and reconstructed Z position, respectively, also in millimeters, using the scale on the left. Note the excellent alignment and linearity, minus the strange outliers around 2.2m.
- The yellow and green curves are tracking error standard deviations in X and Y, respectively, in millimeters, using the scale on the right. (X, Y) tracking error grows linearly with distance, but is so small that it does not show up.
- The maroon curve is tracking error standard deviation in Z, in millimeters, using the scale on the right. Z tracking error grows quadratically with distance, as predicted by the mathematical formulation, and starts becoming very noisy itself at larger distances because the error is dominated by the ball’s projection quantization on the camera’s pixel grid.
After placing the PS Move controller in any of the test positions, I collected 5 seconds of video frames, i.e., 150 position measurements (the camera ran at 30Hz), averaged them for the position result (blue curve), and calculated their standard deviations for the error results (yellow, green, and maroon curves).
In the experiment that led to Figure 4, I placed the ball directly in front of the camera, and then moved it to different Z positions. I performed a second experiment where I placed the ball at a fixed distance and moved it laterally (in X), but the results were the same as the first experiment: X error standard deviation constant and on the order of fractions of a millimeter, and Z error standard deviation constant but randomly affected by X placement, probably due to different alignments with the camera’s pixel grid, and in general much larger than X error standard deviation.

Interesting article! Does PSVR use this method?
I can’t know for sure, but I’m assuming they are using this algorithm, just based on everything else about PSVR being as good as possible given the constraints of the PlayStation.
How can one calculate the “direction vectors” from “intrinsic camera properties”? Is there any article or examples of that?
This article shows the intrinsic parameters and some algorithms to calculate them. You can google for “OpenCV camera calibration” to find a bunch of tutorials using OpenCV. The formulas in the article describe how to calculate the pixel coordinate for a given 3D position. Invert those formulas to calculate a 3D position (assuming some fixed z) for a given pixel coordinate.
can we get a github or code of the thing ?
“Step 1 is a basic image processing problem, namely blob extraction”
I’m not sure this is so basic in the general case. Does your algorithm need you to manually give it the correct HSV values of the sphere or can it automatically discover them from a source image with a known sphere location? Also, in your demo video the lights are off so the background does not overlap any of the sphere’s HSV values making segmentation easy. What about under a wide variety of lightning conditions and background colors where there can be some overlap? Simply using the sphere’s absolute HSV parameters for segmentation won’t always be good enough; sometimes you’ll have to narrow them and lose some of the sphere itself in order to sufficiently segment it from the background. Just wondering how robust this part of your algorithm is.
(This person)[https://www.pyimagesearch.com/2015/09/14/ball-tracking-with-opencv/] solves a problem similar to yours, although he determines good HSV values manually.